Alignment and Padding
Background
上篇文章Unaligned Fault - Defect Raised by Compiler Optimization里提出了疑问,编译器是怎么在内存中安排所定义变量的。本文将用一些示例来展示结果。
Compiler: (Arm GNU Toolchain 13.3.Rel1 (Build arm-13.24)) 13.3.1 20240614
Data Model
在开始这个话题前有必要知道各个数据类型的长度是如何定义的。有童鞋会问,这不是定好的吗?比如char是1B,int是4B。规定好的不假,然而不同的data model里,数据长度有可能是不同的。主要的data model有LP32,ILP32,LLP64,ILP64,LP64。下表列出在各个data model下,不同数据类型的长度:
| type | LP32 | ILP32 | LLP64 | ILP64 | LP64 |
|---|---|---|---|---|---|
| char | 8b | 8b | 8b | 8b | 8b |
| short | 16b | 16b | 16b | 16b | 16b |
| int | 16b | 32b | 32b | 64b | 32b |
| long | 32b | 32b | 32b | 64b | 64b |
| long long | 64b | 64b | 64b | 64b | 64b |
| pointer | 32b | 32b | 64b | 64b | 64b |
aarch32默认的data modle为ILP32 aarch64默认的data modle为LP64
Alignment and Padding
上文里提到,非对齐访问对比对齐访问,在硬件实现上要加另外的逻辑,在软件上又会降低性能,所以编译器会默认会把变量按照对齐的方式放置,比如下面的例子:
1
2
3
4
uint8_t a;
uint16_t b;
uint8_t c;
uint32_t d;
编译来看看实际是如何放置的。这里要注意的是,c中变量所在的位置有三种情况,bss, data,or stack,申明如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
uint8_t a_bss;
uint16_t b_bss;
uint8_t c_bss;
uint32_t d_bss;
uint8_t a_data = 1;
uint16_t b_data = 2;
uint8_t c_data = 3;
uint32_t d_data = 4;
void print_address(void)
{
uint8_t a_stack;
uint16_t b_stack;
uint8_t c_stack;
uint32_t d_stack;
printf("a_stack = 0x%x\n", (unsigned int)(uintptr_t)&a_stack);
printf("b_stack = 0x%x\n", (unsigned int)(uintptr_t)&b_stack);
printf("c_stack = 0x%x\n", (unsigned int)(uintptr_t)&c_stack);
printf("d_stack = 0x%x\n", (unsigned int)(uintptr_t)&d_stack);
printf("a_bss = 0x%x\n", (unsigned int)(uintptr_t)&a_bss);
printf("b_bss = 0x%x\n", (unsigned int)(uintptr_t)&b_bss);
printf("c_bss = 0x%x\n", (unsigned int)(uintptr_t)&c_bss);
printf("d_bss = 0x%x\n", (unsigned int)(uintptr_t)&d_bss);
printf("a_data = 0x%x\n", (unsigned int)(uintptr_t)&a_data);
printf("b_data = 0x%x\n", (unsigned int)(uintptr_t)&b_data);
printf("c_data = 0x%x\n", (unsigned int)(uintptr_t)&c_data);
printf("d_data = 0x%x\n", (unsigned int)(uintptr_t)&d_data);
}
结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
a_stack = 0xf9206270
b_stack = 0xf9206272
c_stack = 0xf9206271
d_stack = 0xf9206274
a_bss = 0xf92062e0
b_bss = 0xf92062e2
c_bss = 0xf92062e4
d_bss = 0xf9206318
a_data = 0xf9206390
b_data = 0xf9206392
c_data = 0xf9206394
d_data = 0xf9206398
通过结果可以看到,所有的变量都是对齐的,但在stack中的变量做了重排,节省了4个字节的空间。下面来直观的看下区别:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
bss, data:
3 2 1 0
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| b | Reserved | a |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Reserved | c |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| d |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
stack:
3 2 1 0
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| b | c | a |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| d |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
结构又和变量的排列有区别。此外还要明确当前使用的是data model(后续例子都以LP64为例)。看下例:
1
2
3
4
5
6
typedef struct {
uint8_t a;
uint16_t b;
uint8_t c;
uint32_t d;
} test1_t;
对于结构编译器是不会重排节省空间的,所以它的layout如下:
1
2
3
4
5
6
7
8
3 2 1 0
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| b | Reserved | a |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Reserved | c |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| d |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
是不是很简单?如果是结构套结构呢?
1
2
3
4
5
6
7
8
9
10
11
typedef struct {
uint8_t a;
uint8_t b;
uint8_t c;
} test2_t;
typedef struct {
uint8_t a;
uint8_t b;
test2_t c;
} test3_t;
在结构套结构的时候就把内层结构展开,而不是以内层结构的大小做对齐。这里结果是5。
1
2
3
4
5
typedef struct {
uint8_t a;
uint64_t b;
uint8_t c;
} test4_t;
还有这个,结果是24,因为要保证uint64_t的对齐,所以结构的size是其中最大的基本类型的整数倍。既然这样,猜一下下面这个结构所占的size。
1
2
3
4
typedef struct {
uint64_t a;
uint8_t b;
} test5_t;
总结如下:
- 结构中每个变量都要放在对齐的位置
- 结构套结构的时候,把内层结构展开
- 结构大小总是其中最大数据类型大小的整数倍
另外在某些特殊应用里,开发者不想让编译器把结构做对齐,也可以用__attribute__((packed))来定义结构,这样得到的size就是结构中所以变量size的和。
1
2
3
4
typedef struct {
uint64_t a;
uint8_t b;
} __attribute__((packed)) test6_t;
上面定义的结构在内存中占用的字节就是8 + 1 = 9B。
这里还有另外一个可以限定范围的pack,如下:
1
2
3
4
5
6
7
8
#pragma pack(push)
#pragma pack(1)
//or #pragma pack(push, 1)
typedef struct {
uint64_t a;
uint8_t b;
} test7_t;
#pragma pack(pop)
上例中在push/pop范围内struct的定义都遵循1B alignment。pop后则恢复默认。当然并非所有的编译器都支持这种方式(本文中所用arm compiler是支持的)。
最后附一张对齐非对齐的表以供参考。
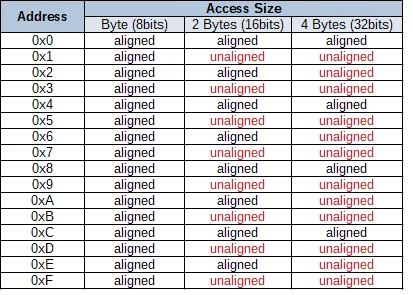
Reference
Why LP64?
Alignment, Padding and Data Packing
Data Structure Alignment
Deep Dive
Data Alignment Problems
Data Alignment, Padding, and Optimization Techniques