Unaligned Fault - Defect Raised by Compiler Optimization
Background
上个周末有个客户量产项目出了些问题,被拉进群里做support,也真是够牛马的,周六干到深夜两点,周日熬到10点,周一本来想轮休下,又有新问题,又搞到10点,这还是外企风格不!!!不过量产顺利推进也是开心的,顺带总结经验教训。
Unaligned Access Fault
要理解这个错误是什么,首先要知道在计算机系统里什么叫unaligned access,以及为什么不能或者不建议unaligned access。
The alignment of the access refers to the address being a multiple of the transfer size. For example, an aligned 32 bit access will have the bottom 4 bits of the address as 0x0, 0x4, 0x8 and 0xC assuming the memory is byte addressed.
An unaligned address is then an address that isn’t a multiple of the transfer size. The meaning in AXI4 would be the same.
如上所述,地址是需要读写的数据长度的整数倍的时候就是aligned access,否则就是unaligned access。当然这要从机器角度去考虑,不是说随便3字节,7字节都可以align,一般size都是2的几次方,比如1B,2B,4B等等。之前在Harm of Dead Store Elimination里一些汇编也展示了这一点,从1B,2B到32B都有汇编指令可以操作。
那为什么不建议unaligned access?查阅资料如下:
- Some architectures are able to perform unaligned memory accesses transparently, but there is usually a significant performance cost.
- Some architectures raise processor exceptions when unaligned accesses happen. The exception handler is able to correct the unaligned access, at significant cost to performance.
- Some architectures raise processor exceptions when unaligned accesses happen, but the exceptions do not contain enough information for the unaligned access to be corrected.
- Some architectures are not capable of unaligned memory access, but will silently perform a different memory access to the one that was requested, resulting in a subtle code bug that is hard to detect!
总结下来,也不是不能实现,但performance不是太好。在举例之前先说另外一个事。
Computers commonly address their memory in word-sized chunks. A word is a computer’s natural unit for data. Its size is defined by the computers architecture. Modern general purpose computers generally have a word-size of either 4 byte (32 bit) or 8 byte (64 bit).
也就是主流系统中processor其实每次从总线取的数据位宽都是一样的(即便是burst也是这个size的整数倍)。比如aarch64中,这个位宽一般是8 Bytes。下面是个简单的例子:
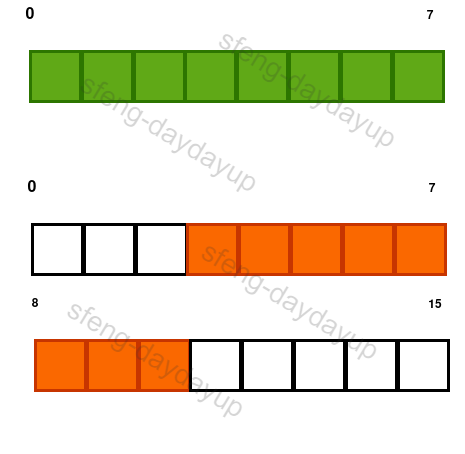
假如操作地址是0x0,则如图中绿色部分所示,一次传输全部完成,而如果操作地址为0x3,则先传输5 Bytes,第二次再传过来3 Bytes(不考虑burst),另外还需要做移位操作,看起来就挺麻烦的。早先的SoC甚至都不支持这种操作,并把这种行为定义为unaligned fault。实操中确实需要从0x3的地址读取8个字节就要软件自己处理了。
关于Arm对unaligned access的支持,文档里有说明,原文copy如下:
The Arm®v6 architecture, with the exception of Armv6-M, introduced the first hardware support for unaligned accesses. Cortex®-A and Cortex-R processors can deal with unaligned accesses in hardware, removing the need for software routines.
Support for unaligned accesses is limited to a subset of load and store instructions:
- LDRB, LDRSB, and STRB.
- LDRH, LDRSH, and STRH.
- LDR and STR.
Instructions that do not support unaligned accesses include:- LDM and STM.
- LDRD and STRD.
虽然有支持,一方面硬件增加了这部分实现逻辑,变复杂了,另一方面,使用前需要配置,在Armv8-A中由SCTLR的{A, nAA}控制,另外还有其他条件,比如只对Normal memory有效(Cache enable?),Device memory无效。这也大概印证了总线协议中AXI支持非对齐访问,而AHB和APB则不支持(想支持就得加另外的硬件组合逻辑)。
How is Unaligned Access Produced
实际上编译器为了提供程序执行效率,在编译过程中会把数据按对齐方式放置(这个值得单独写一篇),但为啥还会有非对齐访问呢?主要由于:
- 指针操作
1
uint32_t *data = (uint32_t *)(0x3);
- 对非对齐数据的数据结构增加__attribute__((packed))属性
1 2 3 4
typedef struct { uint8_t a; uint32_t b; } __attribute__((packed)) test_struct_t;
- 手写汇编代码
1 2
mov x1, #0x7 str wzr, [x1]
当然,上述只是举例,实际例子中大多隐蔽性很强。
本文标题中提到的由编译器优化带来的非对齐访问错误属于哪种呢?都是,又都不是。看下面这段代码。编译并查看汇编。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
typedef struct {
uint8_t a;
uint8_t b;
uint8_t c;
} unaligned_test_t;
unaligned_test_t unaligned_test[2];
void unaligned_testfunc(int i)
{
unaligned_test[i].a = 1;
unaligned_test[i].b = 2;
unaligned_test[i].c = 3;
unaligned_test[1 - i].a = 4;
unaligned_test[1 - i].b = 5;
unaligned_test[1 - i].c = 6;
}
Compiler: (Arm GNU Toolchain 13.3.Rel1 (Build arm-13.24)) 13.3.1 20240614
先用O1(O0也可以,生成的代码更多)来编。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
0000000000002bd0 g O .bss 0000000000000006 unaligned_test
00000000000018a4 <unaligned_testfunc>:
18a4: b0000002 adrp x2, 2000 <exception_handler>
18a8: 912f4042 add x2, x2, #0xbd0
18ac: 93407c01 sxtw x1, w0
18b0: 8b20c421 add x1, x1, w0, sxtw #1
18b4: 8b010043 add x3, x2, x1
18b8: 52800024 mov w4, #0x1 // #1
18bc: 38216844 strb w4, [x2, x1]
18c0: 52800041 mov w1, #0x2 // #2
18c4: 39000461 strb w1, [x3, #1]
18c8: 52800061 mov w1, #0x3 // #3
18cc: 39000861 strb w1, [x3, #2]
18d0: 52800021 mov w1, #0x1 // #1
18d4: 4b000020 sub w0, w1, w0
18d8: 93407c01 sxtw x1, w0
18dc: 8b20c420 add x0, x1, w0, sxtw #1
18e0: 8b000041 add x1, x2, x0
18e4: 52800083 mov w3, #0x4 // #4
18e8: 38206843 strb w3, [x2, x0]
18ec: 528000a0 mov w0, #0x5 // #5
18f0: 39000420 strb w0, [x1, #1]
18f4: 528000c0 mov w0, #0x6 // #6
18f8: 39000820 strb w0, [x1, #2]
18fc: d65f03c0 ret
用Os(或者O2)编译。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
0000000000002bb0 g O .bss 0000000000000006 unaligned_test
0000000000001788 <unaligned_testfunc>:
1788: 937f7c01 sbfiz x1, x0, #1, #32
178c: b0000002 adrp x2, 2000 <exception_handler>
1790: 912ec042 add x2, x2, #0xbb0
1794: 8b20c021 add x1, x1, w0, sxtw
1798: 8b020023 add x3, x1, x2
179c: 52804024 mov w4, #0x201 // #513
17a0: 78216844 strh w4, [x2, x1]
17a4: 52800061 mov w1, #0x3 // #3
17a8: 39000861 strb w1, [x3, #2]
17ac: 52800021 mov w1, #0x1 // #1
17b0: 4b000020 sub w0, w1, w0
17b4: 5280a083 mov w3, #0x504 // #1284
17b8: 937f7c01 sbfiz x1, x0, #1, #32
17bc: 8b20c020 add x0, x1, w0, sxtw
17c0: 8b020001 add x1, x0, x2
17c4: 78206843 strh w3, [x2, x0]
17c8: 528000c0 mov w0, #0x6 // #6
17cc: 39000820 strb w0, [x1, #2]
17d0: d65f03c0 ret
比较汇编可以看到,当用O1及以下编译的时候,很规矩,用strb每次写一个字节。而再看用Os编译的汇编,看这几行:
1
2
3
4
5
6
7
8
......
179c: 52804024 mov w4, #0x201 // #513
17a0: 78216844 strh w4, [x2, x1]
......
17b4: 5280a083 mov w3, #0x504 // #1284
......
17c4: 78206843 strh w3, [x2, x0]
......
为了提高效率,编译器把两个strb合并成了一个strh,而根据以下这行:
1
0000000000002bb0 g O .bss 0000000000000006 unaligned_test
unaligned_test在bss里占了6个字节,起始地址为0x2bb0。由此推出:
| 变量 | 地址 | 赋值 |
|---|---|---|
| unaligned_test[0].a | 0x2bb0 | 1 |
| unaligned_test[0].b | 0x2bb1 | 2 |
| unaligned_test[0].c | 0x2bb2 | 3 |
| unaligned_test[1].a | 0x2bb3 | 4 |
| unaligned_test[1].b | 0x2bb4 | 5 |
| unaligned_test[1].c | 0x2bb5 | 6 |
那么,无论unaligned_testfunc的输入参数为0还是1,都会遇到strh的地址参数为奇数,也就是unaligned access。神奇吧!!!编译器优化出问题了!!!
这里有两个问题:
- unaligned_test_t unaligned_test[2]为啥这样安排
- Os(O2)与O1什么差异导致的这个问题
关于#1,博主打算另写一篇文章来总结align和padding。关于#2,参看Optimize Options后发现O其中有一个增加的优化选项叫-fstore-merging。那就用“-Os -fno-store-merging”编译看结果。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
0000000000001788 <unaligned_testfunc>:
1788: 937f7c01 sbfiz x1, x0, #1, #32
178c: b0000002 adrp x2, 2000 <exception_handler>
1790: 912ec042 add x2, x2, #0xbb0
1794: 8b20c021 add x1, x1, w0, sxtw
1798: 8b010043 add x3, x2, x1
179c: 52800024 mov w4, #0x1 // #1
17a0: 38216844 strb w4, [x2, x1]
17a4: 52800041 mov w1, #0x2 // #2
17a8: 39000461 strb w1, [x3, #1]
17ac: 52800061 mov w1, #0x3 // #3
17b0: 39000861 strb w1, [x3, #2]
17b4: 52800021 mov w1, #0x1 // #1
17b8: 4b000020 sub w0, w1, w0
17bc: 52800083 mov w3, #0x4 // #4
17c0: 937f7c01 sbfiz x1, x0, #1, #32
17c4: 8b20c020 add x0, x1, w0, sxtw
17c8: 8b000041 add x1, x2, x0
17cc: 38206843 strb w3, [x2, x0]
17d0: 528000a0 mov w0, #0x5 // #5
17d4: 39000420 strb w0, [x1, #1]
17d8: 528000c0 mov w0, #0x6 // #6
17dc: 39000820 strb w0, [x1, #2]
17e0: d65f03c0 ret
果然,合并strb的操作消失了。破案了,哈哈
Solution to Avoid Unaligned Fault
关于这个问题怎么解决,有以下几个。
- 如上提到的,加选项“-fno-store-merging”
但这只解决store的问题,还有load呢? - 使用“violatile”修饰词(这也是遇到这个问题最初的一个fix)
也可以,不过解决的alignment问题仅限于开发者能注意到的变量,很多隐藏的还是没解决,也不能每个都加volatile,performance要受影响了。 - 申明struct为__attribute__((packed))
编译发现并没有改善。示例结构里都是uint8_t,本来就是packed。另外证明这个属性只影响空间布局。 - 牛人的大招来了,编译选项“-mstrict-align”
最初提出这个选项的时候,博主还有些犹豫,因为一个稳定运行很久的系统由于编译选项的变化出问题也不是遇到一次了,后来仔细查看了这个选项的功能,确实是个safe的compile option。而且可以一次性解决所有的unaligned access的问题。当然代价也是有的,类似store-merge之类的优化就没了。“strict-align indicates that the compiler should not assume that unaligned memory references are handled by the system.”
其实还可以enable CPU的unaligned access,但这样改动稍大,如前所述,要硬件支持,对于Arm还只对Normal memory有效。另外performance也一样受影响,如果代码有跨多平台移植需求就更不推荐了。
最后再提一嘴,关于编译选项变化引起bug,严格说来,这次遇到的问题就是一种表现。但归根到底还是code写的不够严谨。写code并非只需关注软件逻辑,还需要了解硬件运行机制,编译器行为等等。我等40+码农踩过不少坑(吃过的盐!走过的路!嘿嘿),广大公司应该摒弃年龄歧视,踊跃提供岗位,另外,我等也不能沾沾自喜,学海无涯,永无止境!!!(太励志了吧,哈哈)
Reference
What’s unaligned address access
Unaligned Memory Accesses
Alignment
Unaligned Access Support
strict-align
Optimize Options